The Illusion of Randomness
(updated 9/28
to include gambling, the square-root
rule,
the great coin flip experiment, and the
old baseball page)
© 2001 Richard A.
Muller
Radioactivity and the Gambler's paradox
As I mentioned in class, humans tend to see patterns when, in fact, the results are completely random. When listening to a Geiger counter, we all get the impression that the radioactive decays are clumped. And yet, they are all independent and random. The same phenomena is sometimes called the "Gambler's Paradox." Someone who is placing bets looks for patterns and bets to take advantage of them. But the patterns aren't really there (the fall of the ball on the roulette wheel really is random -- at least at an honest casino), and so the gambler who is looking for patterns and 'streaks' is really only fooling himself. Every spin is independent, with equal chance to come up red or black, equal chance to hit any number between 0 and 99. The fact that the last 5 hits were black doesn't mean that you can now predict that the next one will be black too.
Nor does a string of blacks mean that the next one will be red. That might be the logic of a gambler who says, "in the end, it all has to even out." In fact, it doesn't have to even out. In the end, if the number of times it came up red is expected to be 10,000, then from the square-root rule, we really expect it only to be within the range of 10,000 ± squareroot(10,000) = 10,000 ± 100. Note that with more spins of the wheel, the squareroot gets larger. So it doesn't have to even out!
We will give several other examples of the randomness paradox: constellations of random stars, and the batting streaks in baseball.
"Constellations" of random stars
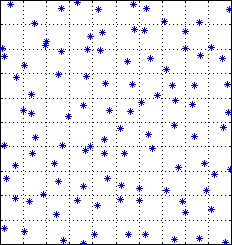
The same phenomena -- seeing patterns in random data -- occurs with random patterns of points. Using a computer, I generated completely random locations. I assigned each location to a "star" and then I made the plot. It is shown on the left.


To get a more uniform plot, I then redid all the calculations, but in a different way. I divided the box into 100 smaller boxes, and put one star in each little box. However the location in the little box was random. The result is the figure on the right.
Which pattern looks more random? Most people would say: the pattern on the right! The left diagram seems to be full of clumps, lines, vacant regions. The left diagram seems to be full of "constellations," groupings of stars that don't seem random.
It is hard to believe that the diagram on the right is the non-random one. In the figure below (on the left) I duplicated the more uniform star pattern, but also put in dotted lines, showing explicitly the 100 little boxes. The star pattern is exactly the same as for the plot on the upper right. But now you can verify that no box contains two stars. The stars were spread out in this matter to make the coverage more uniform. That makes it look more random! But it is an illusion.

In the actual sky, there are some stars that are not randomly placed. The stars in the cluster known as the Pleiades are truly clustered. But most of the stars are randomly placed. The stars in the constellation of Orion are not even close to each other; some are much farther away than others. We see what appear to be constellations, because truly random patterns appear clustered. We have to make them more uniform to make them look random. That is why many paintings of stars look wrong. The artist did not make the stars sufficiently random.
Here is a CHALLENGE, possibly worth one extra quiz point: find me examples of paintings by great artists that are even better examples of "overly-uniform stars. I want only paintings that are 1900 or earlier; no 20th or 21st century. Note: you earn a quiz point only if you are the first person to suggest a particular painting, and the painting does indeed show stars -- either randomly painted, or uniformly, or something of similar interest to us. I am not interested in stars that show only the star of Bethlehem, for example, or are an attempt to portray the Big Dipper. I want stars that are supposed to look like real stars, and either succeed, or don't. Please, no more paintings by Van Gogh; I have all of those from other students. I will grant two points if the painting was done prior to 1900! (I recently spent a day in the Louvre looking for such paintings, and found stars were not depicted by any early painters! Art history students in the class -- why is this?
The best submission to the Challenge, as of September 21, 2002, is the book cover displayed to the right on the figure above. (Thank you, Poorwa Singh, for submitting this one!) Do you think the stars in this are random or nonrandom?
I'd still like to find such a painting by one of the great masters. (If you know the name of the painting and the artist, then I can probably find a copy online by using Google in the "advanced" mode.)
The one rule of statistics that everyone should know is the square root rule. In fact, you will be amazed to see how important it is! This is the way it works: if, based on past performance, you expect to have an event happen 1000 times, then don't be surprised if it actually happens 1032 times, or 968 times. Where did I get those numbers? First, I take the squareroot of 1000. That is 32. Then I both add it, and subtract it, from 1000. That gives me the expected range. That's the squareroot rule.
Is the squareroot rule ever violated? Yes -- about 1/3 of the time! That is pretty frequent. So if you expected the event to occur 1000 times, and it actually occurred 1050 times (that is bigger than 1032), then you are surprised, but not too surprised. The squareroot is called the "standard deviation". The standard deviation for 1000 events is 32. For 100 events, it is 10. For 1,000,000 events, it is 1,000. The rules of statistics say that you will exceed twice the standard deviation only 5% of the time. That still happens, of course. You exceed three standard deviations only 0.3% of the time. That still happens about one time in 300.
Take a look at the stars in the truly random pattern. How many stars do you expect to find on the left side of the square? Partial answer: 50. That is because they are random, so you expect half to be on half the page. But a much better answer is 50 ± 7. Then you wouldn't be surprised if you found 43 or 57. If you look at the figure on the right side, the uniformly distributed one, you will of course find exactly 50.